
On Latency
Going down the rabbit hole to understand latency
Table of contents
Motivation
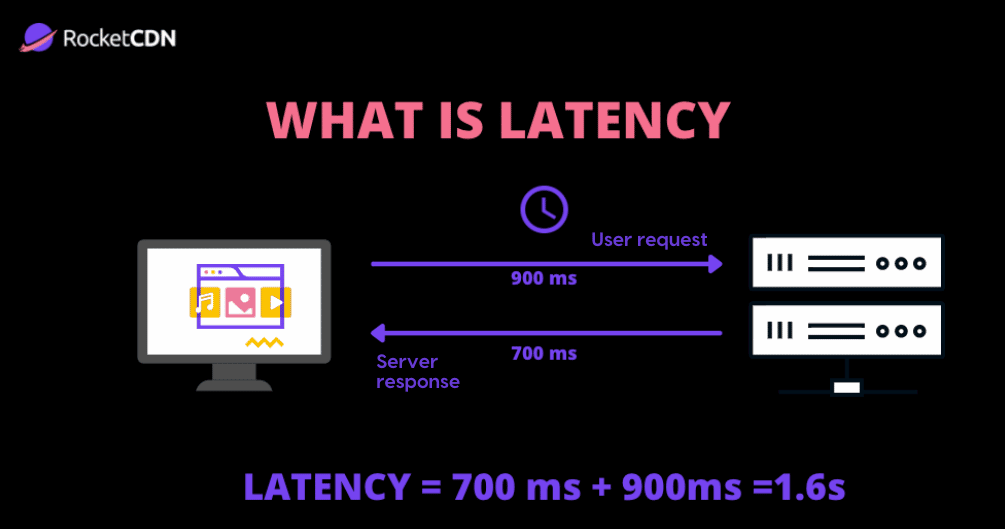
Latency is the delay or time it takes for data to travel from one point to another on a network. It’s measured in milliseconds and directly affects how long you wait for a response online. Low latency means faster responses, while high latency results in noticeable delays. A great way to visualize this is through Grace Hopper’s demonstration, where she used wires to represent the tiny fractions of time involved in computing.
If you need more convincing about why latency matters, watch this video on latency arbitrage. For example, Stock X might trade at $100 on Exchange A and $100.05 on Exchange B. A firm can detect the delay, buy on A, and sell on B within milliseconds to make a profit. Latency can be crucial in industries like finance.
Now that we understand its importance, let’s dive deeper. To build a stronger intuition for latency, check out these latency testing tools here and here
Is 100 Milliseconds Too Fast?
The paper “Is 100 Milliseconds Too Fast?” by James R. Dabrowski and Ethan V. Munson examines the commonly held belief that software applications must respond to user inputs within 100 milliseconds to appear instantaneous. Their research aimed to determine if this threshold is accurate by identifying the actual detection limits for delays in graphical user interfaces.
Key Findings:
- Detection Thresholds: Through experiments involving various user interface actions—such as clicking menu buttons, typing, and interacting with dialogs—the study found that users began to notice delays at approximately 150 to 200 milliseconds, varying slightly depending on the specific action.
- Implications for Design: These findings suggest that the traditional 100-millisecond guideline may be overly conservative. Designers and engineers could consider slightly longer response times without negatively impacting user perception.
- Variability Among Actions: The study also noted that the sensitivity to delays varied with different types of interactions, indicating that a one-size-fits-all threshold may not be appropriate for all user interface elements.
In summary, Dabrowski and Munson’s research challenges the strict 100-millisecond rule, proposing that user interfaces can remain responsive and user-friendly even with slightly longer response times, depending on the context of the interaction.
Note - I tried looking for this well-regarded and cited paper Is 100 Milliseconds Too Fast?” by James Dabrowski (2001) , but could not . Ended up asking ChatGPT about the major takeaways
Patterns Of Low Latency - Pekka Enberg
The second resource we would refer to is the video here
- Why is latency important?
- Bad latency leads to unhappy customers
- Takes work to improve tail latency ( see below )
- Many users experience bad latency of just one component ( since it compounds )
- Measuring Latency
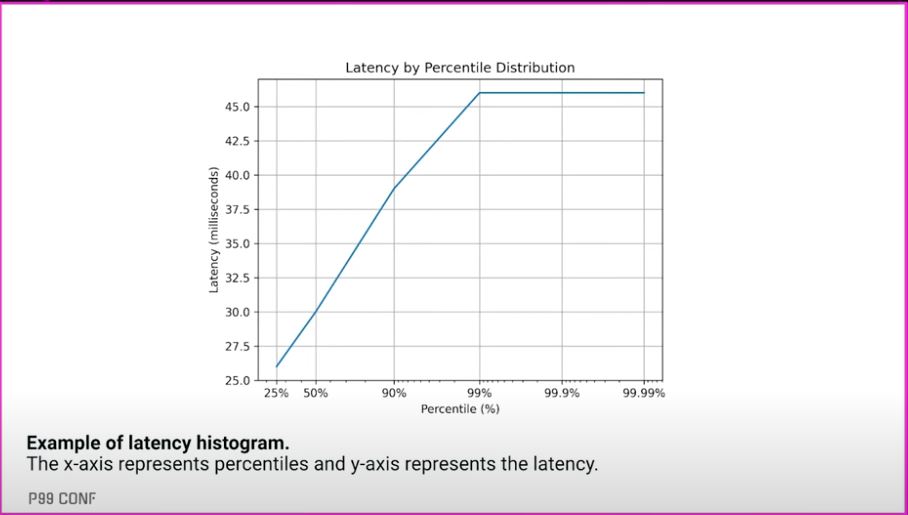
- Latency is a distribution, so measure it as such
- Avg latency is not an interesting metric
- Max latency is an interesting metric but hard to optimize
- the 99th percentile or beyond is a good compromise ( see below )
- beware of co-ordinated omission ( see below )
- Histograms are good for measuring latency ( eCDF’s are better to visualize tail latency, Marc Brooker has a good post )
- Reducing latency
- Latency is everywhere
- Three key ways to reduce latency
- avoid data movement: data movement is slow.
- Colocation: Move 2 components closer. Not always possible, unless you have multiple copies
- Replication and caching: both can be used with impact on consistency
- avoid work
- Avoid algorithmic complexity: Big-O
- Better memory management: Avoid dynamic memory allocation, Avoid demand paging
- Code optimization: Use of profiler
- CPU-intensive computation: Avoid long-running tasks or split the work
- avoid waiting
- Don’t wait for the network: use TCP_NODELAY
- Don’t wait for OS
- use wait-free synchronization
- eliminate synchronization: multi-threaded programming, partition data
- avoid data movement: data movement is slow.
Explain Like I am 12..thanks chatGPT
- Tail latency - Here’s a way to understand tail latency using the restaurant example: Imagine you’re meeting a group of friends at a restaurant. Most of them arrive within 10-15 minutes, but there’s always one friend who shows up 30-40 minutes late. Even though most of the group is on time, you can’t start eating until everyone is there. This late-arriving friend represents tail latency – the slowest response in a system. Even if most requests (or friends) are quick, the system’s overall performance (or dinner experience) is held up by the slowest ones. Reducing tail latency is crucial because, like waiting for that friend, a system’s performance is often limited by its slowest operations.
- p99 - Imagine you’re throwing 100 paper planes to see how far they fly. Most of them land pretty close, but a few go much farther or shorter.P99 latency is like saying, “Out of those 100 planes, 99 landed within a certain distance, but that 1 plane went way farther (or slower in computer terms). It means 99% of things happen quickly, but the slowest 1% takes much longer. When people talk about reducing P99 latency, they’re trying to make sure even the slowest 1% of tasks don’t take forever—just like making sure that the last plane doesn’t fly too far away!
- Coordinated omission happens when a system accidentally hides the worst delays during latency measurements, making the system look faster than it really is.
Imagine this:
You’re timing how long it takes for a friend to reply to your texts. If your friend replies quickly, you send another text right away. But if they take forever to respond, you wait patiently and don’t send the next message until they reply.The problem? You’re not measuring how long they could have taken if you had kept sending messages.
In latency testing:
- Fast requests keep coming.
- Slow requests get ignored because the system gets “stuck,” and no new requests are sent during that delay. This hides the real impact of slowdowns, just like you not texting while waiting hides how slow your friend is overall. Why It Matters: Coordinated omission gives a false sense of security. The system looks good under normal conditions but can fail badly under heavy load. Real-world systems face constant requests, so it’s important to measure how the system behaves even during slowdowns.
- Demand Paging: Demand paging is a memory management technique where the operating system only loads parts of a program into memory when they are needed.
Imagine it like this:
You have a big book, but instead of carrying the whole book everywhere, you only tear out and bring the pages you need to read at that moment. If you need another chapter, you go back and get more pages.
How it works:
When a program starts, only the essential parts (like the first few instructions) are loaded into memory. If the program tries to access something that isn’t loaded yet, the operating system pauses the program, loads the missing part, and then continues. This is called a page fault – the system realizes a required “page” (a chunk of memory) isn’t in memory, so it fetches it from disk.
Why it’s useful:
- Saves memory – Only what’s needed is loaded, leaving more room for other programs.
- Faster start-up – Programs don’t have to load fully before running.
- Efficient use of resources – Unused parts of a program stay on disk until necessary. However, too many page faults can slow things down – just like constantly running back for more pages can get tiring.
- TCP_NODELAY : TCP_NODELAY is a setting that controls how data is sent over a network using the TCP protocol. By default, TCP waits for a certain amount of data to accumulate before sending it in a single “chunk” (called a TCP segment) to optimize the number of packets sent over the network. This is known as Nagle’s Algorithm. However, sometimes you want to send data as soon as possible, without waiting for more data to fill up the segment. This is where TCP_NODELAY comes in.