
On LLM Evals
LLMs hallucinate.Your job is to ensure they don’t embarrass you, your company, or your brand.
Table of contents
- Introduction
- Choosing the right LLM
- Human Evaluation – HHH Framework
- Scaling Evaluation – LLM as Judges
- Hands-On exercise to run evals
Introduction
LLMs are powerful but unpredictable. Unlike traditional software, they don’t always give the same answer to the same input. Without structured evaluation, you’re flying blind — you can’t guarantee quality, safety, or trust. Evals are how you make sure your AI is reliable enough to put in front of customers. Enter LLLm Evals .
- AI evals are like unit tests for agents.
- Difference between software testing vs AI evals:
- Software testing & unit tests are deterministic. LLM agents are non-deterministic, with multiple possible paths.
- Integration tests rely on code/docs, but improving agents relies on data.
Part 1 - Choosing the right LLM
- Start with requirements along these dimensions
- Accuracy: example >90% ideal in legal contexts.
- Latency: Medium–low is acceptable for offline jobs.
- Cost: Less sensitive initially since manual legal review is expensive.
- Context length: for example Must handle long docs (≈20K–1M tokens).
- Throughput (QPM): Size for expected query volume.
- Grounding: Model should cite source contract text.
- Some benchmarksyou could use , typically published by models -
- Language understanding
- Q&A
- Document classification
- Reasoning (planning, chain-of-thought)
- Tool usage (email, APIs, CRM)
- Model Selection Use published evals/model cards (e.g., a “model matrix”) to compare options. Example: O3 High mini may offer a strong balance of accuracy, latency, and cost.
Part 2 Human Evaluation – HHH Framework
- Helpful → Solves problem, complete, succinct.
- Honest → Factual, validated, clickable links.
- Harmless → Ethical, legal, policy-aligned, guardrails applied.
- How to use:
- Define north star metrics: Job completion, customer satisfaction.
- Create yes/no evaluation questions.
- Human evaluators score against ground truth.
- Define launch thresholds (e.g., 60% helpfulness).
- Update criteria with customer feedback.
Start with this simple framework
Part 3 Scaling Evaluation – LLM as Judges
- Challenge: Human eval doesn’t scale.
- Solutions:
- Cloud APIs for moderation (toxicity, hate speech, frustration).
- Train an LLM judge using good conversation examples.
- Use SDKs or pre-built judges to measure: correctness, relevance, guideline adherence, context sufficiency, RAG chunk relevance.
- Process:
- Collect requests + responses + ground truth → apply judges → score → dashboard metrics.
- Continuous improvement: Judges improve over time but still an evolving field.
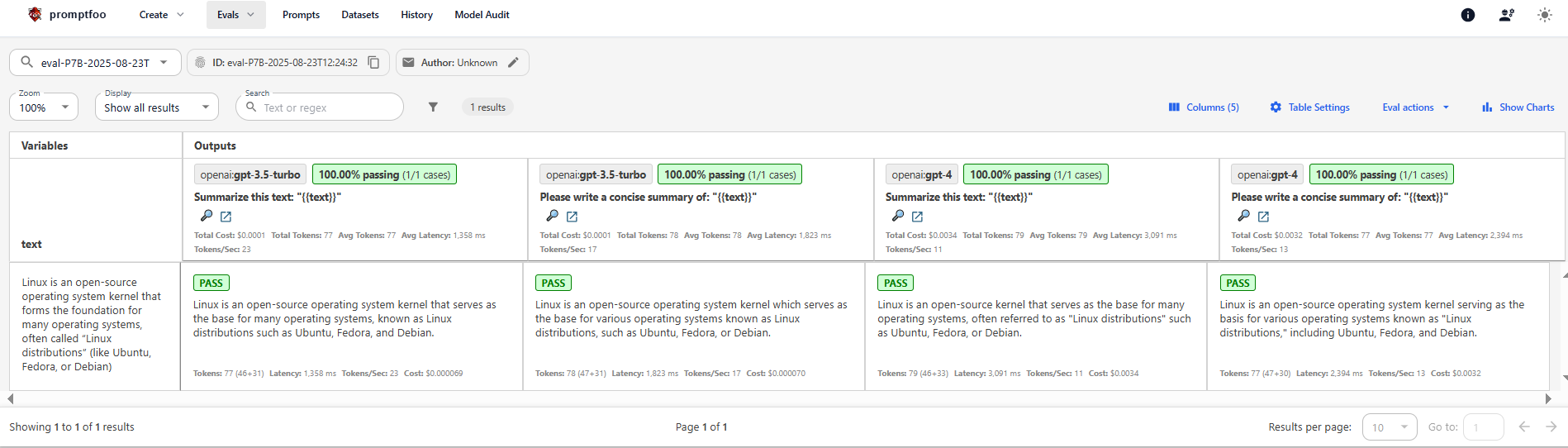
## Part 4 Hands-On exercise to run a few evals
- PromptFoo is a test-driven development framework for LLMs
- Install Node.js & npm (nodejs.org)
- Set up your OPENAI_API_KEY environment variable
- Configure promptfooconfig.yaml. Mine Here
- npm install -g promptfoo
- run this to run the evaluations npx -y promptfoo eval -c «config».yaml
- run this to see the results in the browser like below - npx -y promptfoo view -p 8080
Written on August 23, 2025